2001-01-14 ... 2022-01-24
array(['2001-01-14T00:00:00.000000', '2001-01-16T00:00:00.000000',
'2001-01-17T00:00:00.000000', '2001-01-19T00:00:00.000000',
'2001-01-20T00:00:00.000000', '2001-01-22T00:00:00.000000',
'2001-01-24T00:00:00.000000', '2002-01-14T00:00:00.000000',
'2002-01-16T00:00:00.000000', '2002-01-17T00:00:00.000000',
'2002-01-19T00:00:00.000000', '2002-01-20T00:00:00.000000',
'2002-01-22T00:00:00.000000', '2002-01-24T00:00:00.000000',
'2003-01-14T00:00:00.000000', '2003-01-16T00:00:00.000000',
'2003-01-17T00:00:00.000000', '2003-01-19T00:00:00.000000',
'2003-01-20T00:00:00.000000', '2003-01-22T00:00:00.000000',
'2003-01-24T00:00:00.000000', '2004-01-14T00:00:00.000000',
'2004-01-16T00:00:00.000000', '2004-01-17T00:00:00.000000',
'2004-01-19T00:00:00.000000', '2004-01-20T00:00:00.000000',
'2004-01-22T00:00:00.000000', '2004-01-24T00:00:00.000000',
'2005-01-14T00:00:00.000000', '2005-01-16T00:00:00.000000',
'2005-01-17T00:00:00.000000', '2005-01-19T00:00:00.000000',
'2005-01-20T00:00:00.000000', '2005-01-22T00:00:00.000000',
'2005-01-24T00:00:00.000000', '2006-01-14T00:00:00.000000',
'2006-01-16T00:00:00.000000', '2006-01-17T00:00:00.000000',
'2006-01-19T00:00:00.000000', '2006-01-20T00:00:00.000000',
'2006-01-22T00:00:00.000000', '2006-01-24T00:00:00.000000',
'2007-01-14T00:00:00.000000', '2007-01-16T00:00:00.000000',
'2007-01-17T00:00:00.000000', '2007-01-19T00:00:00.000000',
'2007-01-20T00:00:00.000000', '2007-01-22T00:00:00.000000',
'2007-01-24T00:00:00.000000', '2008-01-14T00:00:00.000000',
'2008-01-16T00:00:00.000000', '2008-01-17T00:00:00.000000',
'2008-01-19T00:00:00.000000', '2008-01-20T00:00:00.000000',
'2008-01-22T00:00:00.000000', '2008-01-24T00:00:00.000000',
'2009-01-14T00:00:00.000000', '2009-01-16T00:00:00.000000',
'2009-01-17T00:00:00.000000', '2009-01-19T00:00:00.000000',
'2009-01-20T00:00:00.000000', '2009-01-22T00:00:00.000000',
'2009-01-24T00:00:00.000000', '2010-01-14T00:00:00.000000',
'2010-01-16T00:00:00.000000', '2010-01-17T00:00:00.000000',
'2010-01-19T00:00:00.000000', '2010-01-20T00:00:00.000000',
'2010-01-22T00:00:00.000000', '2010-01-24T00:00:00.000000',
'2011-01-14T00:00:00.000000', '2011-01-16T00:00:00.000000',
'2011-01-17T00:00:00.000000', '2011-01-19T00:00:00.000000',
'2011-01-20T00:00:00.000000', '2011-01-22T00:00:00.000000',
'2011-01-24T00:00:00.000000', '2012-01-14T00:00:00.000000',
'2012-01-16T00:00:00.000000', '2012-01-17T00:00:00.000000',
'2012-01-19T00:00:00.000000', '2012-01-20T00:00:00.000000',
'2012-01-22T00:00:00.000000', '2012-01-24T00:00:00.000000',
'2013-01-14T00:00:00.000000', '2013-01-16T00:00:00.000000',
'2013-01-17T00:00:00.000000', '2013-01-19T00:00:00.000000',
'2013-01-20T00:00:00.000000', '2013-01-22T00:00:00.000000',
'2013-01-24T00:00:00.000000', '2014-01-14T00:00:00.000000',
'2014-01-16T00:00:00.000000', '2014-01-17T00:00:00.000000',
'2014-01-19T00:00:00.000000', '2014-01-20T00:00:00.000000',
'2014-01-22T00:00:00.000000', '2014-01-24T00:00:00.000000',
'2015-01-14T00:00:00.000000', '2015-01-16T00:00:00.000000',
'2015-01-17T00:00:00.000000', '2015-01-19T00:00:00.000000',
'2015-01-20T00:00:00.000000', '2015-01-22T00:00:00.000000',
'2015-01-24T00:00:00.000000', '2016-01-14T00:00:00.000000',
'2016-01-16T00:00:00.000000', '2016-01-17T00:00:00.000000',
'2016-01-19T00:00:00.000000', '2016-01-20T00:00:00.000000',
'2016-01-22T00:00:00.000000', '2016-01-24T00:00:00.000000',
'2017-01-14T00:00:00.000000', '2017-01-16T00:00:00.000000',
'2017-01-17T00:00:00.000000', '2017-01-19T00:00:00.000000',
'2017-01-20T00:00:00.000000', '2017-01-22T00:00:00.000000',
'2017-01-24T00:00:00.000000', '2018-01-14T00:00:00.000000',
'2018-01-16T00:00:00.000000', '2018-01-17T00:00:00.000000',
'2018-01-19T00:00:00.000000', '2018-01-20T00:00:00.000000',
'2018-01-22T00:00:00.000000', '2018-01-24T00:00:00.000000',
'2019-01-14T00:00:00.000000', '2019-01-16T00:00:00.000000',
'2019-01-17T00:00:00.000000', '2019-01-19T00:00:00.000000',
'2019-01-20T00:00:00.000000', '2019-01-22T00:00:00.000000',
'2019-01-24T00:00:00.000000', '2020-01-14T00:00:00.000000',
'2020-01-16T00:00:00.000000', '2020-01-17T00:00:00.000000',
'2020-01-19T00:00:00.000000', '2020-01-20T00:00:00.000000',
'2020-01-22T00:00:00.000000', '2020-01-24T00:00:00.000000',
'2021-01-14T00:00:00.000000', '2021-01-16T00:00:00.000000',
'2021-01-17T00:00:00.000000', '2021-01-19T00:00:00.000000',
'2021-01-20T00:00:00.000000', '2021-01-22T00:00:00.000000',
'2021-01-24T00:00:00.000000', '2022-01-14T00:00:00.000000',
'2022-01-16T00:00:00.000000', '2022-01-17T00:00:00.000000',
'2022-01-19T00:00:00.000000', '2022-01-20T00:00:00.000000',
'2022-01-22T00:00:00.000000', '2022-01-24T00:00:00.000000'],
dtype='datetime64[us]')
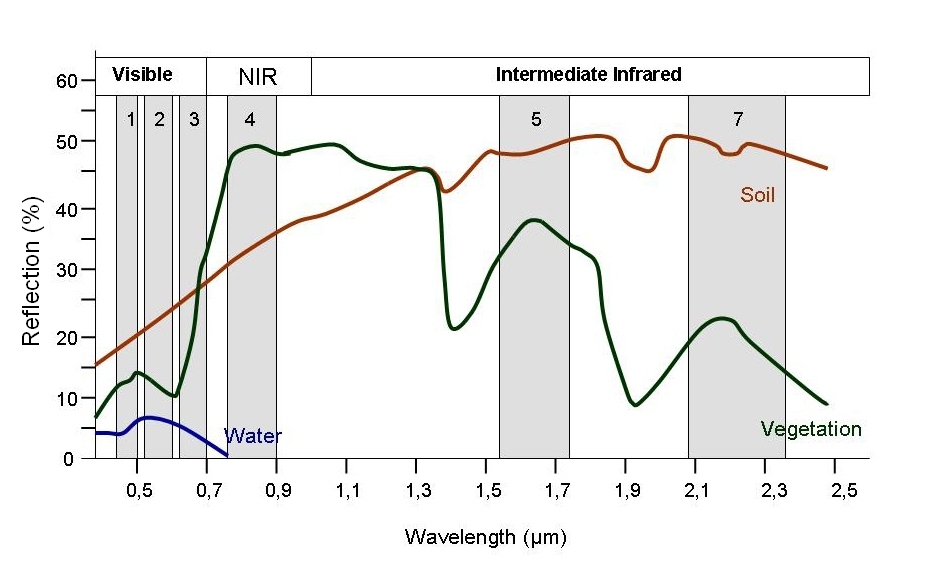 > Image source:
> Image source: 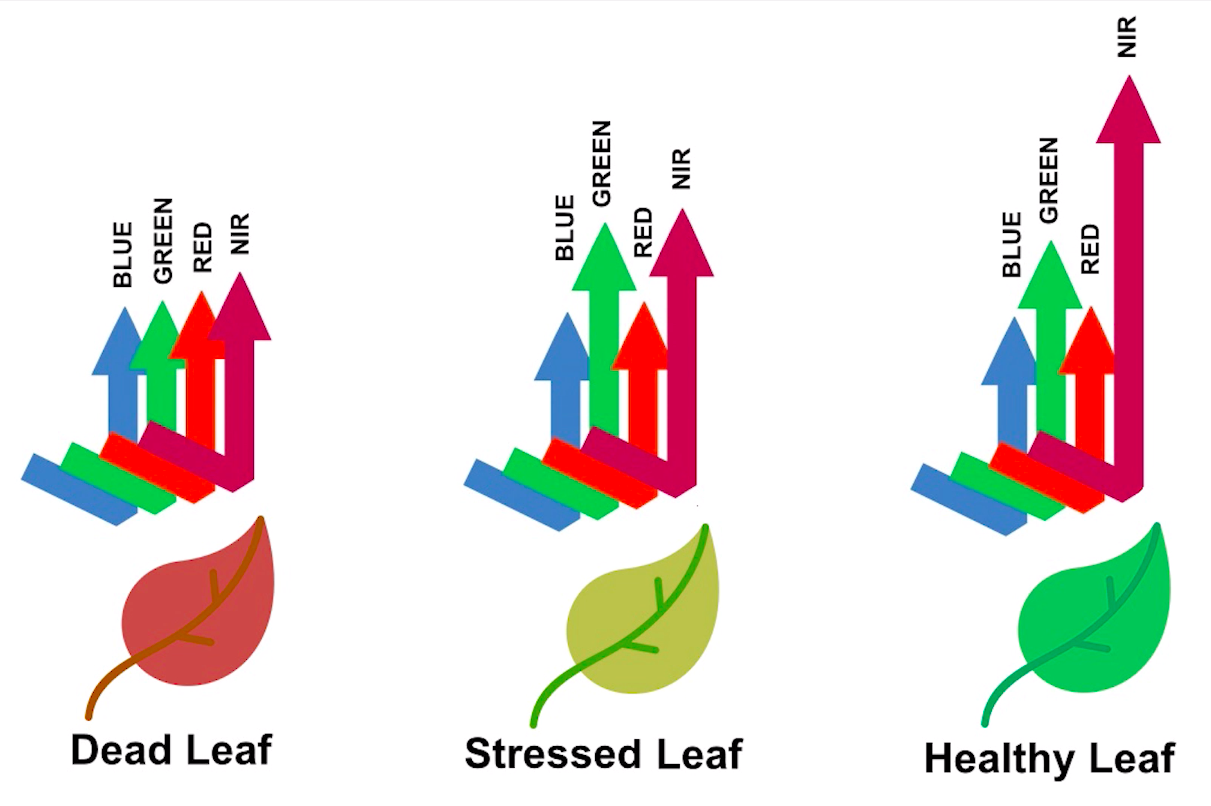 > Image source:
> Image source: